

")

George Graham, Shawn Saavedra and Gladson George all contributed to this piece.
As one of the 3 pillars of Observability, logs help engineers understand applications, troubleshoot anomalies and deliver quality products to customers. ActiveCampaign produces large volumes of logs and has historically maintained multiple fragmented ELK (Elasticsearch, Logstash, and Kibana) implementations across different teams and AWS accounts. Each development team was responsible for the management of their own ELK stack, which led to a wide variance of logging standards, governance, and a limited ability for correlation across ActiveCampaign platforms.
This proved challenging for a few reasons. ELK is expensive at scale, requiring pre-provisioned Elasticsearch storage at a rate of $0.30/GB. Accounting for current and estimated growth, ELK datastores were forecast to grow and cost several 10s of thousands of dollars per month. In addition, log-based alerting is not an option in the open source version of ELK. The ELK stacks were cumbersome to maintain, expensive to operate, and were limiting our ability to efficiently drive correlation of events across our platforms and alert driven responsiveness to critical events when they did manifest.
After embarking on an extensive research of logging and observability platforms, we decided to transition our logging environment to Loki. Loki was chosen for its high performance datastores that are optimized for the efficient storage, indexing, and searching of logs. In contrast to ELK’s multiple components and complex configuration, Loki is designed for ease of setup and management and it works well in distributed microservice environments within Kubernetes and other cloud-based platforms. Loki efficiently compresses storage and its indexing and log querying methodologies are less resource-intensive than ELK. In addition, Loki integrates with Grafana which we use to easily query and visualize the logs. Moreover, Loki can be configured to use S3, which is priced at $0.021/GB and is even more cost-effective as Loki does not require the pre-provisioning of storage for forecasted growth.
We use Grafana as a front end to visualize Loki-based logs, Mimir-based metrics, and will soon be incorporating Tempo-based distributed tracing to create a single pane of glass for logs, metrics, and application performance tracing. This stack will make it easier to derive insight from log data and to correlate them with metrics and application performance characteristics to enhance troubleshooting. We expect this deployment to allow our engineers to more easily identify application and infrastructure behavioral trends and patterns. Grafana allows for alerting to be generated from log and metrics patterns, which has enhanced the monitoring of our platforms, improved the awareness of potential issues, and increased the responsiveness of supporting development teams when issues do start to manifest.
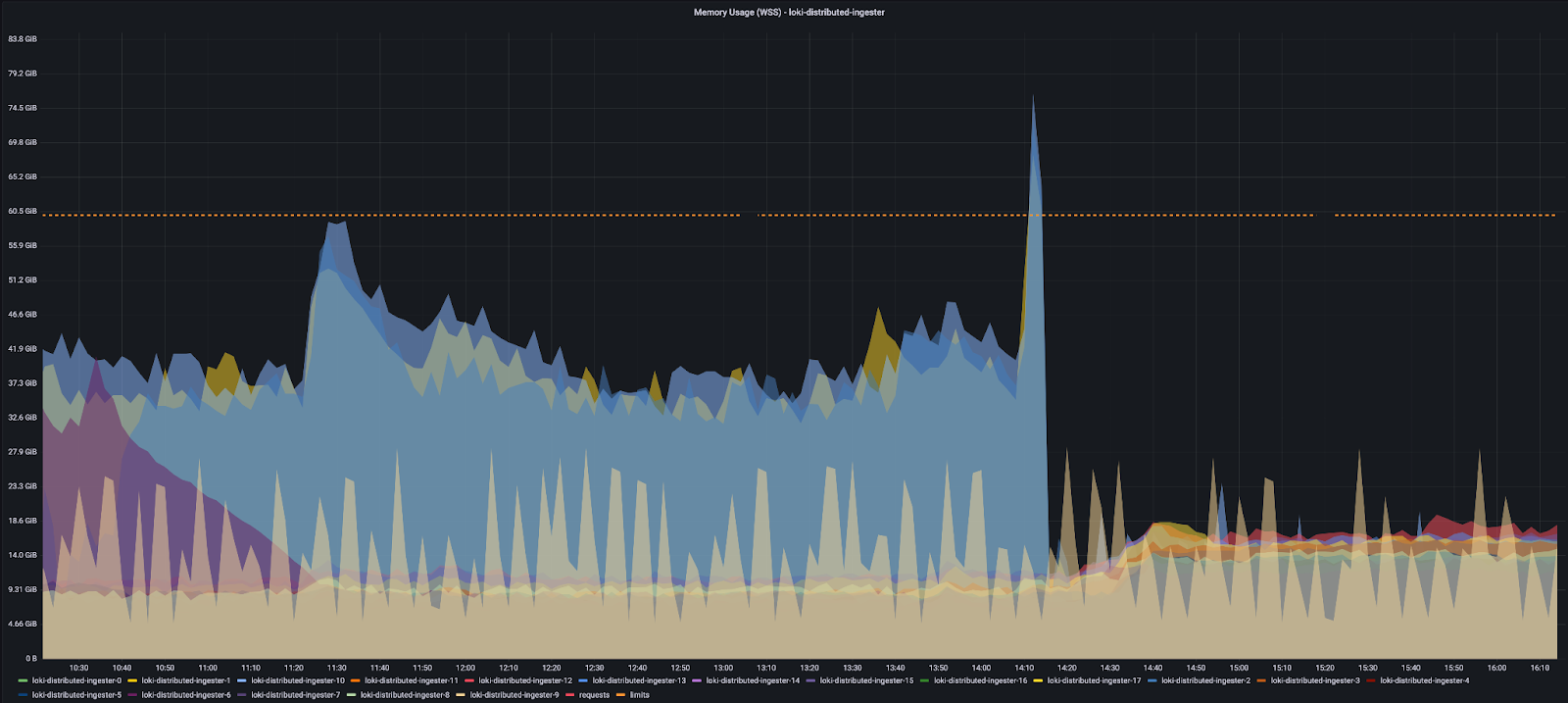
Our initial testing of Loki in pre-production environments successfully demonstrated Loki’s value in providing logging for a uniform and efficient Grafana-based observability platform. However, implementation of Loki in production proved to be more challenging. The production environment had significantly larger log volumes that were sourced from a wider array of distributed platforms and products. This created an imbalance of log streams being processed across the Loki log ingestors and led to frequent “out of memory” errors. To address this issue, we expanded on our labeling strategy by introducing additional labels such as availability zones, environments, products, and customer segmentation to break up log streams into smaller chunks. Because of this, Loki was better able to balance across the log ingestors.
In addition, we identified a third of the log streams required ingestors with 2-3 times higher memory requirements. The chart below shows the positive result after increasing the memory footprint of these ingestors.
Query performance was an additional technical challenge that also benefited from our improved labeling strategy. Querying via LogQL is broken down into 2 parts: Stream Selectors and Log Parsing Pipelines. As with log ingestion, increased layering of labels helps increase query performance. Reducing the volume of logs that are streamed and parsed through label selection in queries improved query performance.
For example, when troubleshooting customer-impacting issues, customer segmentation labels significantly reduce the number of streams Loki retrieves from S3 before applying filters, resulting in quicker response times. Improving and implementing labeling strategies significantly help to balance logging traffic to Loki and improve the log query performance of the Loki platform.
Our initial goal to consolidate our various logging solutions into a cost-effective start of a uniform observability platform was accomplished using Loki and Grafana. Although we experienced initial ingestion and query performance challenges, platform tuning designed to handle higher production log volumes resulted in a high-performing and efficient logging solution.
The Loki logging platform efficiencies also resulted in significant cost reductions. After migrating logs to Loki and shutting down our legacy logging platform, we were able to realize a 73% reduction in log-related hosting costs.

We are proud of the work our engineers have done to upgrade this critical component of our system. As we continue to execute on our unified observability roadmap, we will be integrating metrics and distributed tracing via Mimir and Tempo respectively, creating an observability platform that is expected to improve our ability to deliver highly performant products and features that are more reliable, scalable, secure, cost-effective, and simpler to support.







AUTHOR OF BLOG






Recent Comments